Cluster de Alta Disponibilidad
El objetivo de este práctica es la instalación de una aplicación php (WordPress) sobe dos cluster de alta disponibilidad:
Cluster de HA activo-pasivo
- Utiliza el
Vagrantfilela receta ansible del escenario 6: 06-HA-IPFailover-Apache2+DRBD+GFS2 para crear un cluster de alta disponibilidad activo-pasivo. Nota: La receta instala apache2 + php. - Comprueba que los recursos están configurados de manera adecuada, configura tu host para que use el servidor DNS y comprueba que puedes acceder de forma adecuada a la página.
- Instala en los dos nodos un Galera MariaDB.
- Instala Wordpress en el cluster.
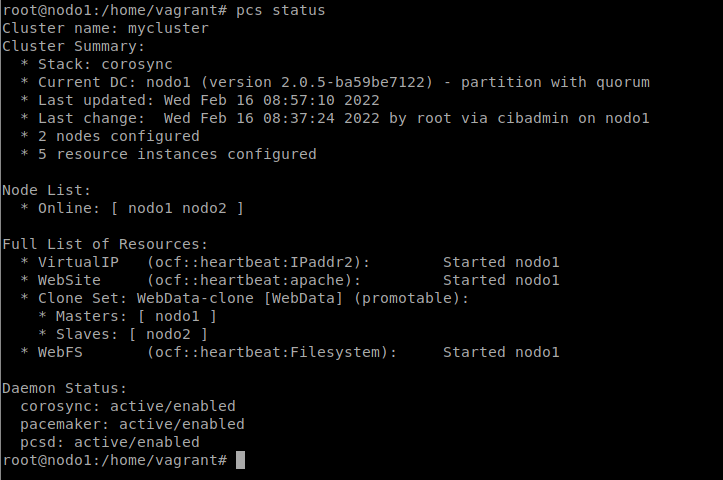
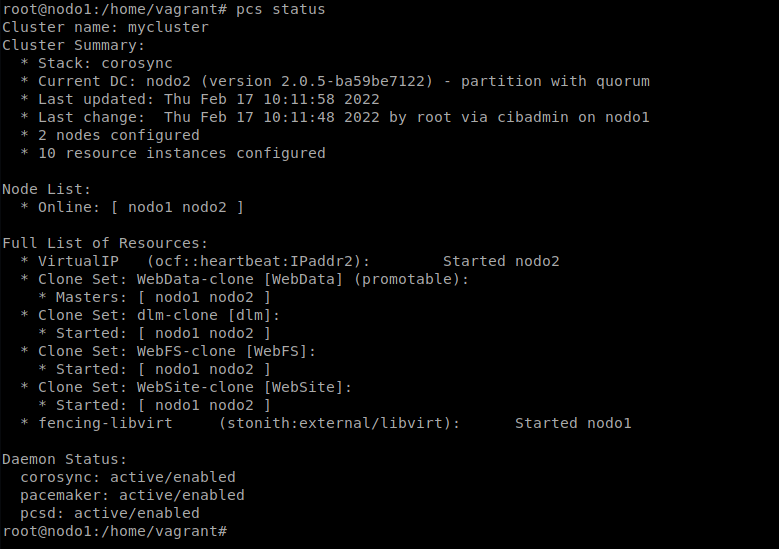
Tras haber levantado el escenario y pasado la receta de ansible, podemos ver que ha configurado el cluster y se han activado los servicios:
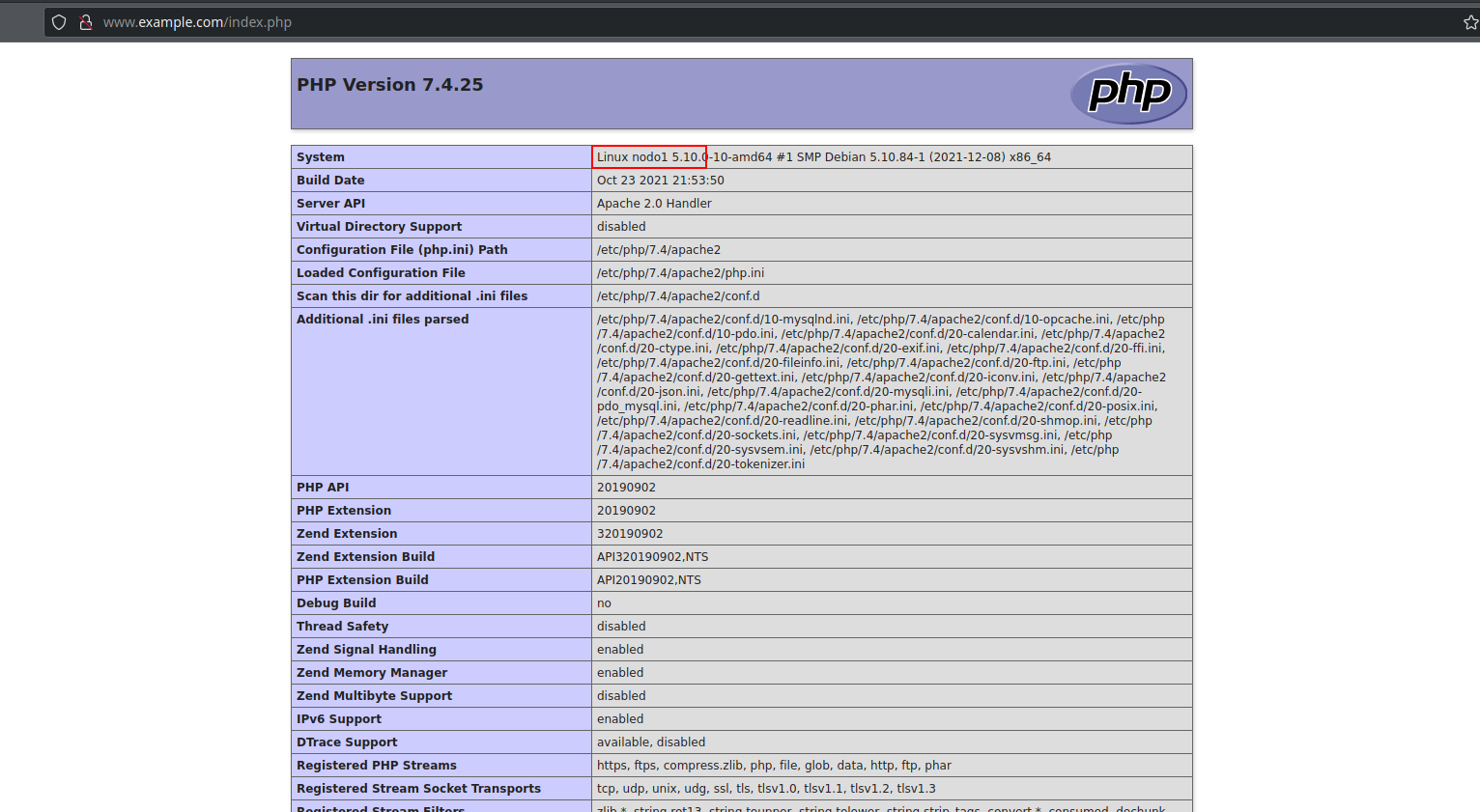
Ahora comprobemos que ambos nodos muestran la página de forma correcta. Para ello, cambiamos la configuración de nuestro anfitrión para que use de servidor dns el “nodo dns” y accedemos a la página:
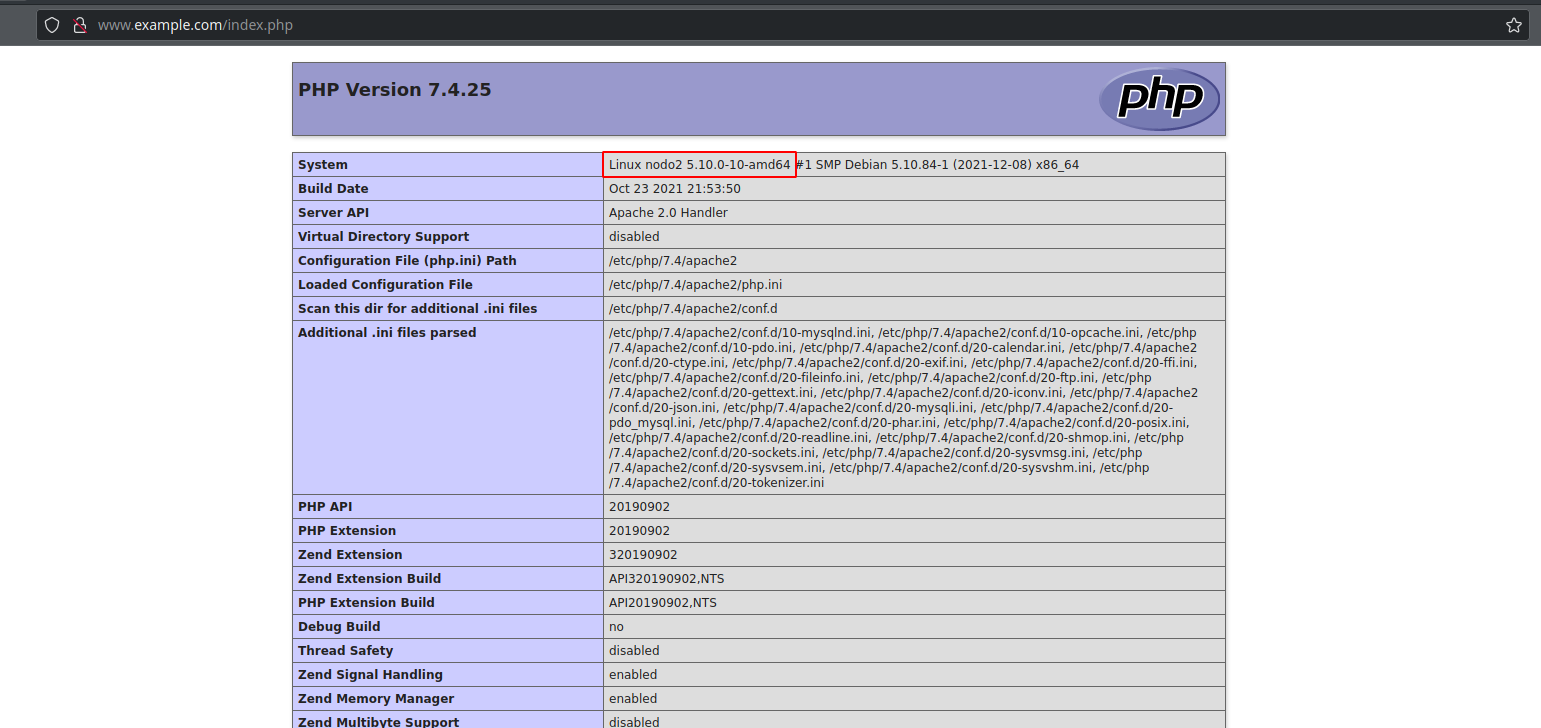
Si apagamos el nodo1, debería poderse seguir visualizando la página en el nodo 2:
A continuación, para tener la base de datos que va a utilizar Wordpress en alta disponibilidad, vamos a instalar Galera MariaDB en ambos nodos. Para ello, en primer lugar, debemos instalar mariadb en ambos nodos:
apt install mariadb-server
También es aconsejable ejecutar el script para securizar mariadb:
mysql_secure_installation
Después, hay que elegir un nodo en el que instalaremos el cluster. En mi caso, he elegido el nodo 1. En primer lugar, detenemos el servicio de mariadb:
systemctl stop mariadb.service
Después hemos de modificar el fichero de configuración del cluster Galera (/etc/mysql/mariadb.conf.d/60-galera.cnf):
nano /etc/mysql/mariadb.conf.d/60-galera.cnf
[galera]
wsrep_on = 1
wsrep_cluster_name = "MariaDB Galera Cluster"
wsrep_provider = /usr/lib/galera/libgalera_smm.so
wsrep_cluster_address = gcomm://10.1.1.101,10.1.1.102
binlog_format = row
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
# Allow server to accept connections on all interfaces.
bind-address = 0.0.0.0
wsrep_node_address=10.1.1.101
Podemos señalar algunos parámetros importantes:
- wsrep_on = 1: Activa el cluster.
- wsrep_cluster_address: Indicamos las IP de los nodos que van a formar parte del cluster.
- bind-address = 0.0.0.0: Permitimos las conexiones a la base de datos desde todas las interfaces de red.
- wsrep_node_address: Dirección IP del nodo que estamos configurando.
A continuación, creamos el cluster e iniciamos el servicio:
galera_new_cluster
systemctl start mariadb.service
Podemos comprobar que se ha creado correctamente si entramos en la base de datos y ejecutamos lo siguiente (todo lo que comienza por wsrep_ hace referencia al cluster):
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 1 |
+--------------------+-------+
1 row in set (0.001 sec)
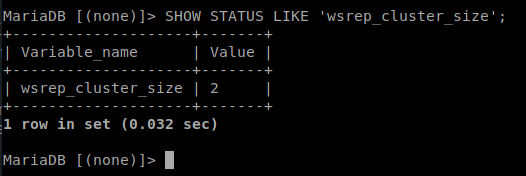
Como vemos, nos indica que el cluster Galera solo tiene un miembro. Ahora añadamos al nodo 2 al cluster. Para ello, en el nodo2, añadimos la misma configuración de antes pero cambiando la ip del nodo2:
[galera]
wsrep_on = 1
wsrep_cluster_name = "MariaDB Galera Cluster"
wsrep_provider = /usr/lib/galera/libgalera_smm.so
wsrep_cluster_address = gcomm://10.1.1.101,10.1.1.102
binlog_format = row
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
# Allow server to accept connections on all interfaces.
bind-address = 0.0.0.0
wsrep_node_address=10.1.1.102
Y reiniciamos el servicio en el nodo2:
systemctl restart mariadb
Ahora, si ejecutamos lo mismo que antes, nos debería indicar que hay dos nodos en el cluster de Galera:
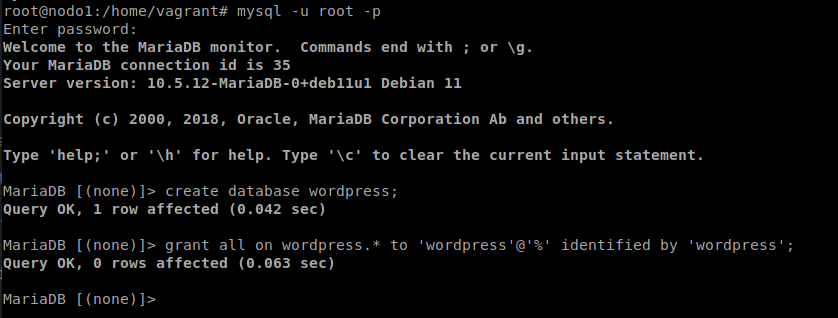
Con el cluster de Galera instalado y funcionando, pasamos a crear la base de datos que usará wordpress:
Ahora nos descargamos e instalamos wordpress en el nodo1 (ya que en este momento es el nodo activo):
cd /var/www/html
wget https://es.wordpress.org/latest-es_ES.tar.gz
tar -xf latest-es_ES.tar.gz
rm latest-es_ES.tar.gz
chown -R www-data: wordpress/
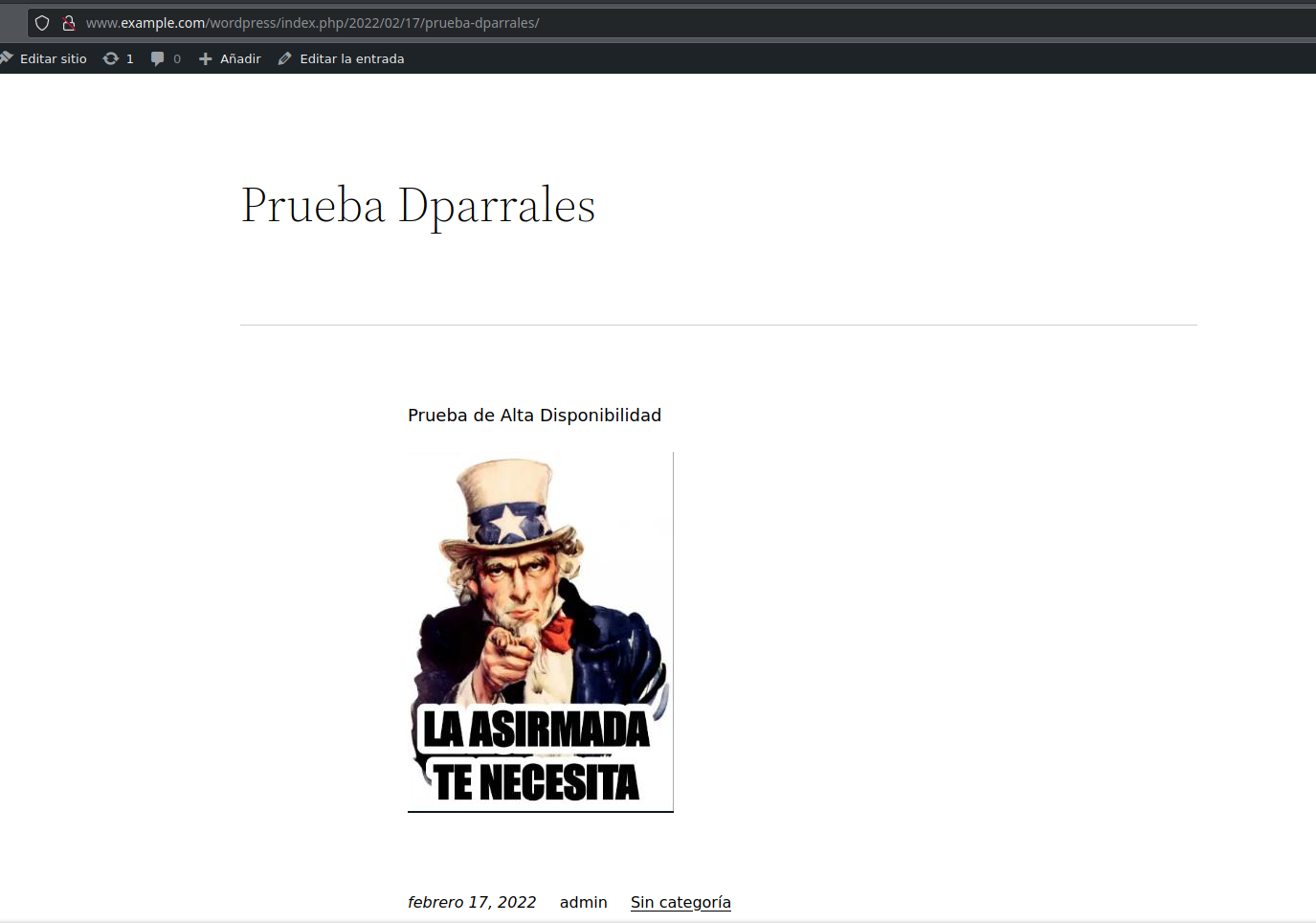
Ahora, entramos en la url y terminamos de instalar wordpress. Una vez hecho esto, entramos en la zona de administración y creamos una entrada que contenga una imagen:
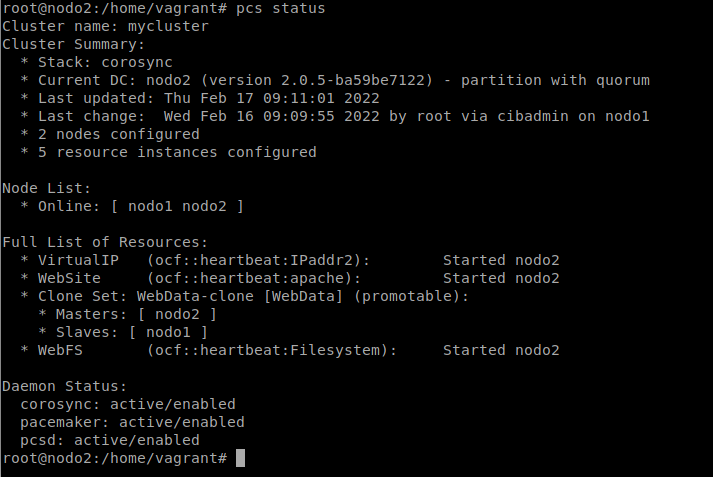
Ahora, si apagamos el nodo1, todos los recursos deberían pasar al nodo2, ya que se encuentra en alta disponibilidad, por lo que la imagen y el post debería poder seguir viéndose:
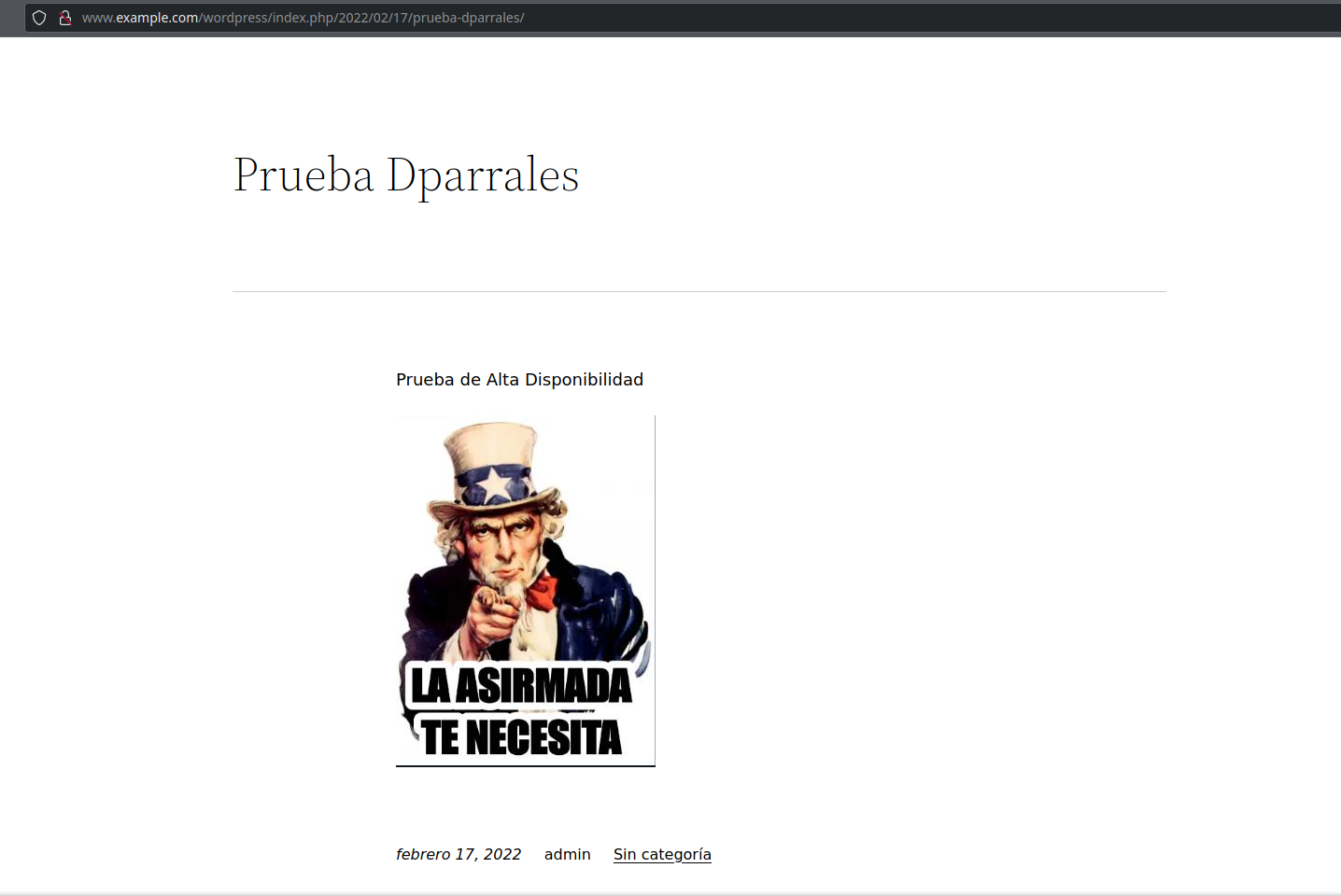
Con esto, podemos dar por finalizada esta parte de la tarea.
Cluster de HA activo-activo
Siguiendo las instrucciones que encuentras en el escenario 6: 06-HA-IPFailover-Apache2+DRBD+GFS2 convierte el cluster en activo-activo. Es necesario instalar el fencing para que el cluster funcione de manera adecuada. Nota: Tienes que tener en cuenta que se va a formatear de nuevo el drbd, por lo que se va a perder el wordpress. Si quieres puedes guardarlo en otro directorio, para luego recuperarlo.
Una vez que el cluster este configurado como activo-activo y WordPress esté funcionado, deberá configurarse un método de balanceo de carga.
En primer lugar, debemos instalar en ambos nodos “GFS2” y el programa DLM, que será el encargado de gestionar el acceso del cluster al almacenamiento distribuido:
apt install gfs2-utils dlm-controld
El DLM debe ejecutarse en los dos nodos, por lo que debemos crear un recurso “ocf:pacemaker:controld”:
pcs cluster cib dlm_cfg
pcs -f dlm_cfg resource create dlm ocf:pacemaker:controld op monitor interval=60s
pcs -f dlm_cfg resource clone dlm clone-max=2 clone-node-max=1
pcs cluster cib-push dlm_cfg --config
Tras esto, podemos ver que se ha creado el recurso:
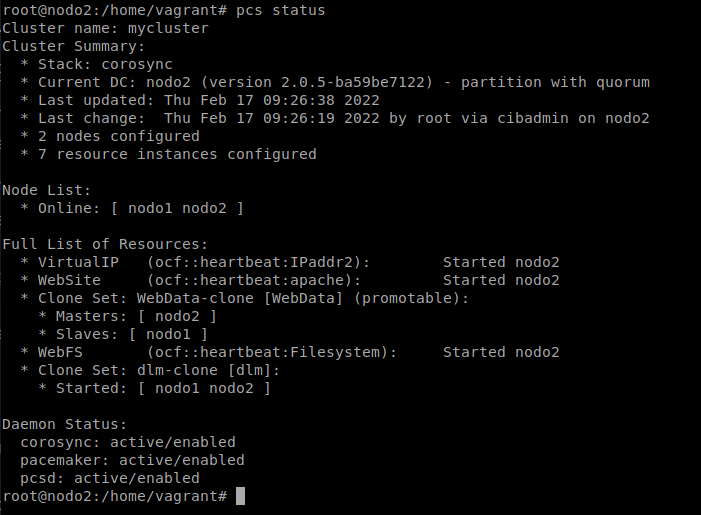
Ahora debemos crear el sistema de archivos “GFS2”, para lo cual debemos deshabilitar primero el recurso que controlaba el sistema de archivos anterior:
pcs resource disable WebFS
Comprobamos que se ha detenido:
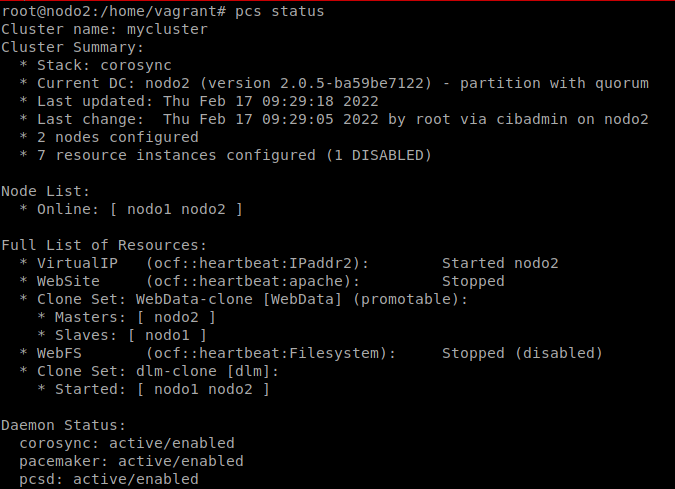
Ya podemos formatear el dispositivo de bloques:
mkfs.gfs2 -p lock_dlm -j 2 -t mycluster:web /dev/drbd1
Donde:
- -p lock_dlm: Indica que vamos a usar el programa DLM (Distributed Lock Manager) para gestionar los cambiso del sistema de archivo.
- -j 2: Se va a reservar espacio para 2 journals (registro donde se almacena información necesaria para recuperar los datos afectados por una transición en caso de que falle) uno para cada nodo.
- -t mycluster:web: El nombre de la tabla de bloqueo (lock) (
web) en el clustermycluster(nombre del cluster que indicamos al crearlo con corosync y que lo podemos encontrar en/etc/corosync/corosync.conf).
Ya podemos guardar información en el dispositivo de bloques:
mount /dev/drbd1 /mnt
cd /mnt/
echo "<h1>Prueba con GFS2</h1>" >> index.html
umount /mnt
Una vez que hemos hecho esto, debemos reconfigurar el recurso del cluster “WebFS” con el nuevo tipo de sistema de fichero:
pcs resource update WebFS fstype=gfs2
GFS2 necesita que DLM este funcionando, por lo que tenemos que poner dos restricciones:
pcs constraint colocation add WebFS with dlm-clone INFINITY
pcs constraint order dlm-clone then WebFS
Por último. debemos montar el recurso del sistema de ficheros WebFS en los dos nodos y modificar el recurso WebData-clone para indicar que ambos se pongan como primarios en el DRBD:
pcs cluster cib active_cfg
pcs -f active_cfg resource clone WebFS
pcs -f active_cfg constraint
pcs -f active_cfg resource update WebData-clone promoted-max=2
pcs cluster cib-push active_cfg --config
pcs resource enable WebFS
Podemos comprobar que los recursos se encuentran activados en los dos nodos, y que ambos nodos son Masters:
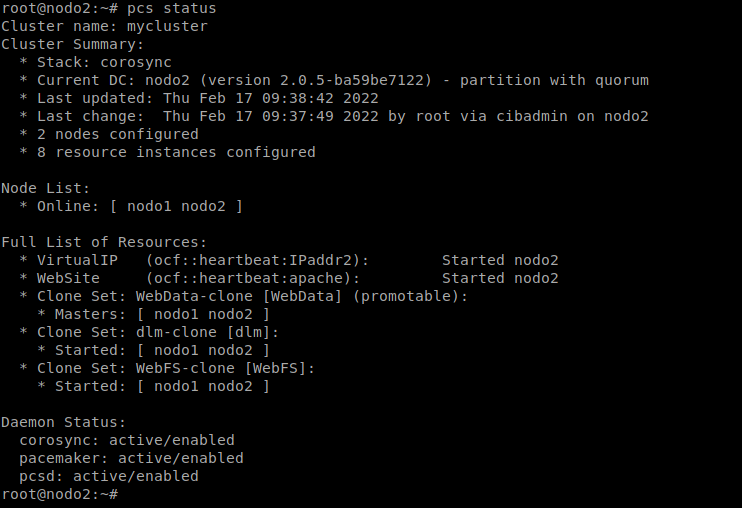
Cualquiera de los servidores web pueden escribir ficheros en /var/www/html, por lo que podemos clonar el recurso WebSite y quitar la restricción de colocación que hacía que el servidor web se activa en el nodo que tenía asignada la VirtualIP:
pcs cluster cib active_cfg
pcs -f active_cfg resource clone WebSite
pcs cluster cib-push active_cfg --config
pcs constraint colocation delete WebSite-clone VirtualIP
Comprobamos:
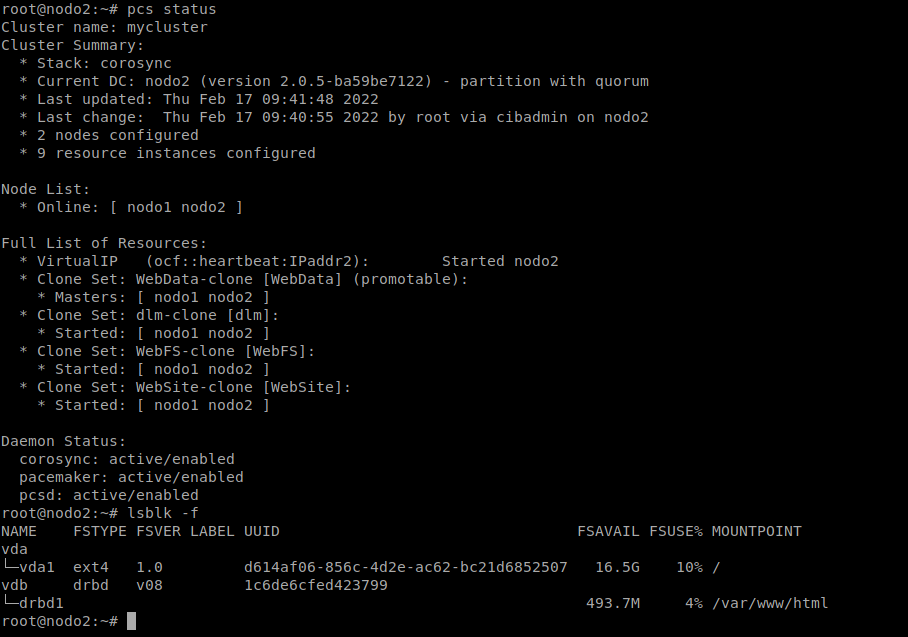
Ahora debemos configurar el “Fencing” y “STONITH”. Podemos ver los agentes que podemos usar ejecutando lo siguiente:
pcs stonith list
Como nosotros estamos haciendo uso de máquina “KVM”, haremos uso del agente external/libvirt. Para ello, primero debemos instalarlo en ambos nodos:
apt install libvirt-clients
Ambos nodos deben ser capaces de acceder al host por ssh con el usuario “root” sin contraseña. Para ello nos generaremos en ambos nodos un par de claves y las añadiremos al host:
ssh-keygen -t rsa
ssh-copy-id 192.168.121.1
Debemos comprobar que parámetros necesitamos configurar en el stonith con este agente. Para ello, ejecutamos lo siguiente:
pcs stonith describe external/libvirt
Y vemos que tenemos que indicar al menos dos parámetros obligatoriamente:
- hostlist: Una lista que relaciona los hostnames de los nodos del cluster con el nombre de la máquina virtual en el hypervisor. En nuestro caso el valor sería:
hostlist="nodo1:06-HA-IPFailover-Apache2DRBDGFS2_nodo1,nodo2:06-HA-IPFailover-Apache2DRBDGFS2_nodo2"
- hypervisor_uri: La uri del sistema de virtualización KVM. En nuestro caso:
qemu+ssh://192.168.121.1/system
Con estos datos, podemos habilitar en fencing en el cluster:
pcs cluster cib stonith_cfg
pcs -f stonith_cfg stonith create fencing-libvirt external/libvirt \
hostlist="nodo1:06-HA-IPFailover-Apache2DRBDGFS2_nodo1,nodo2:06-HA-IPFailover-Apache2DRBDGFS2_nodo2" \
hypervisor_uri="qemu+ssh://192.168.121.1/system"
pcs -f stonith_cfg property set stonith-enabled=true
pcs cluster cib-push stonith_cfg --config
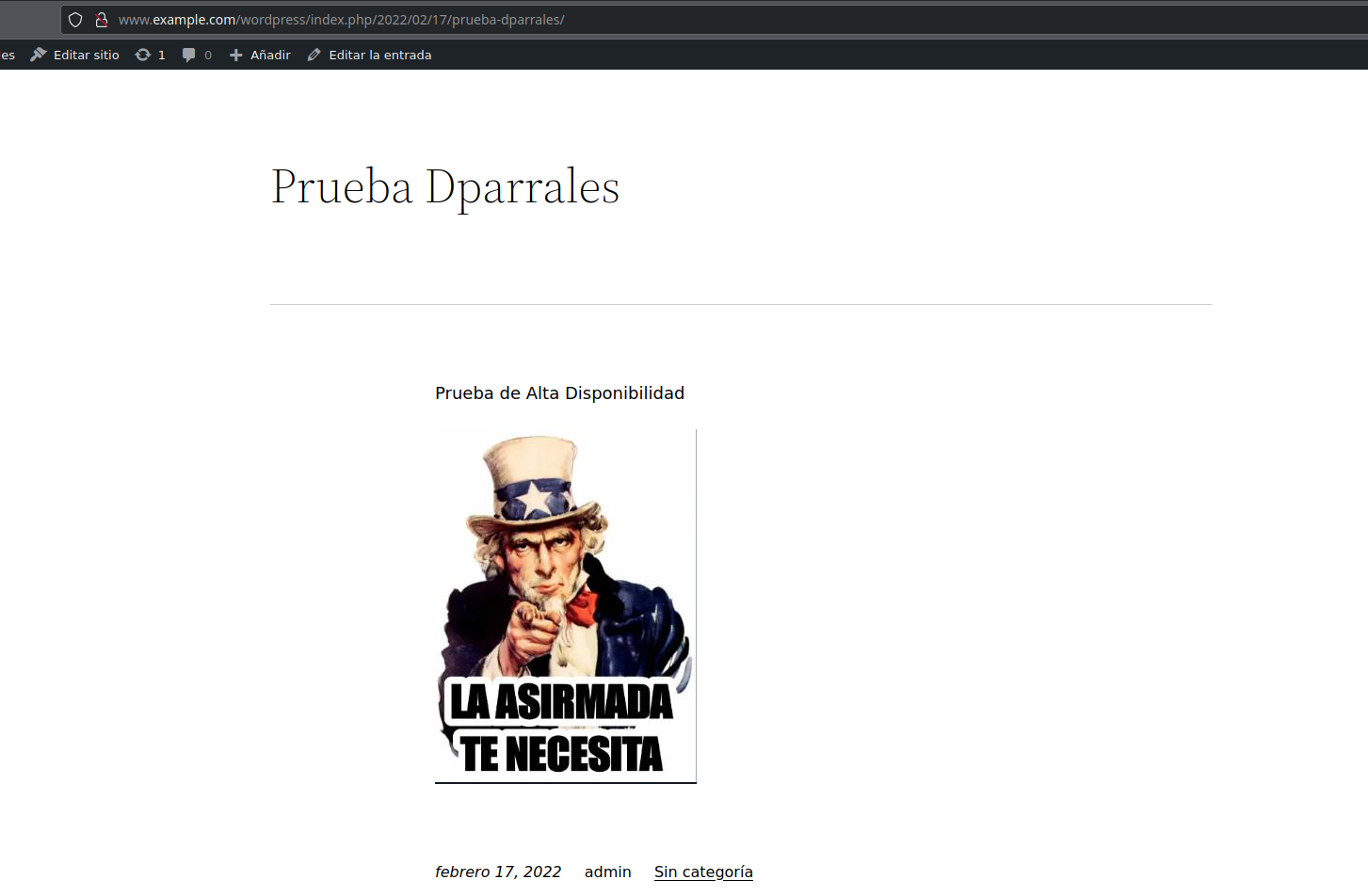
Una vez hecho esto, debemos volver a instalar wordpress, ya que al haber formateado el dispositivo de bloques se ha perdido la información. La instalación de wordpress sigue los mismos pasos que antes. Una vez que hemos configurado la base de datos nos indica que wordpress ya se encuentra instalado (debido a que la información sigue guardada en la base de datos), por lo que podemos acceder con las credenciales antiguas. La imagen que subimos si se perdió, ya que no estaba guardada en la base de datos. Así pues, he vuelto a subir la misma imagen, recuperando el post anterior:
A continuación, instalamos en el nodo “dns” HAproxy para balancear la carga:
apt install haproxy
Y añadimos la siguiente configuración:
nano /etc/haproxy/haproxy.cfg
frontend servidores_web
bind *:80
mode http
stats enable
stats uri /ha_stats
stats auth cda:cda
default_backend servidores_web_backend
backend servidores_web_backend
mode http
balance roundrobin
server backend1 10.1.1.101:80 check
server backend2 10.1.1.102:80 check
También debemos modificar las zonas dns para que apunten a la nueva ip (la del nodo dns):
nano /var/cache/bind/db.10.1.1
103 PTR www.example.com.
nano /var/cache/bind/db.example.com
www A 10.1.1.103
Y reiniciamos el dns:
systemctl restart bind9
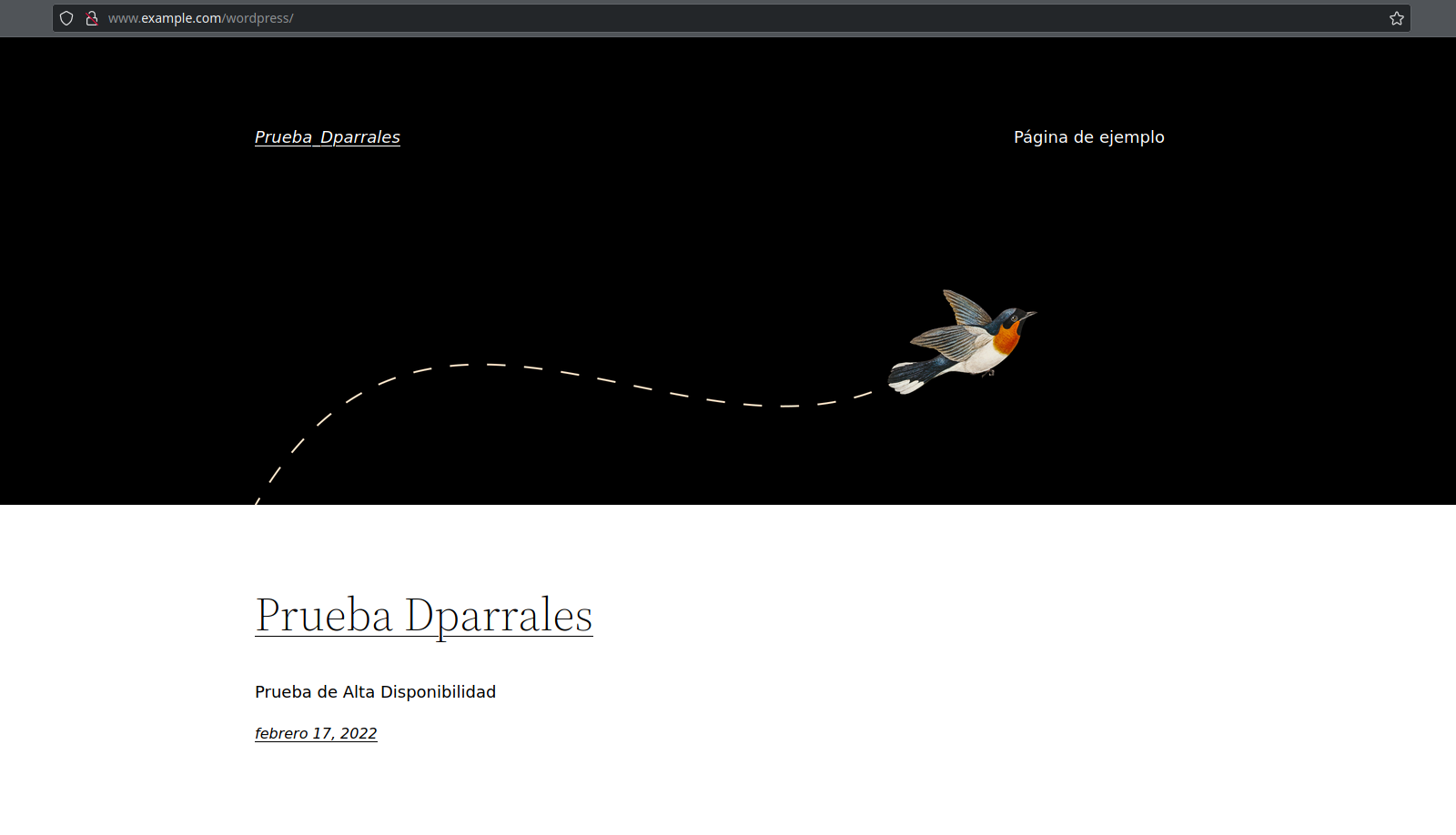
Ahora, si accedemos a la página, la carga se estará balanceando entre los dos nodos aunque no nos demos cuenta:
Con esto, damos por finalizada la práctica.